An Easier Way: Chat to Deploy Llama2 with Walrus
In this blog we will introduce an AI tool, Appilot, to make the deployment simpler

In the previous blog, we explored how to deploy Llama2 on AWS with Walrus. In this blog, we will introduce an AI tool, Appilot, to simplify the deployment.
Appilot ['æpaɪlət] stands for application-pilot. It is an experimental project that helps you operate applications using GPT-like LLMs. Appilot empowers users to execute tasks such as application management, environment management, diagnosis, and hybrid infrastructure orchestration seamlessly through natural language commands.
Prerequisites
Get OpenAI API key with access to the gpt-4 model.
Install python3 and make.
Have a running Kubernetes cluster.
Install Appilot
- Clone the repository.
git clone https://github.com/seal-io/appilot && cd appilot
- Run the following command to get the envfile.
cp .env.example .env
Edit the
.envfile and fill inOPENAI_API_KEY.Run the following command to install. It will create a venv and install required dependencies.
make install
Using Walrus Backend
Walrus serves as the application management engine. It provides features like hybrid infrastructure support, environment management, etc. To enable Walrus backend, you need to install Walrus first and edit the envfile:
Set
TOOLKITS=walrusFill in
OPENAI_API_KEY,WALRUS_URLandWALRUS_API_KEY
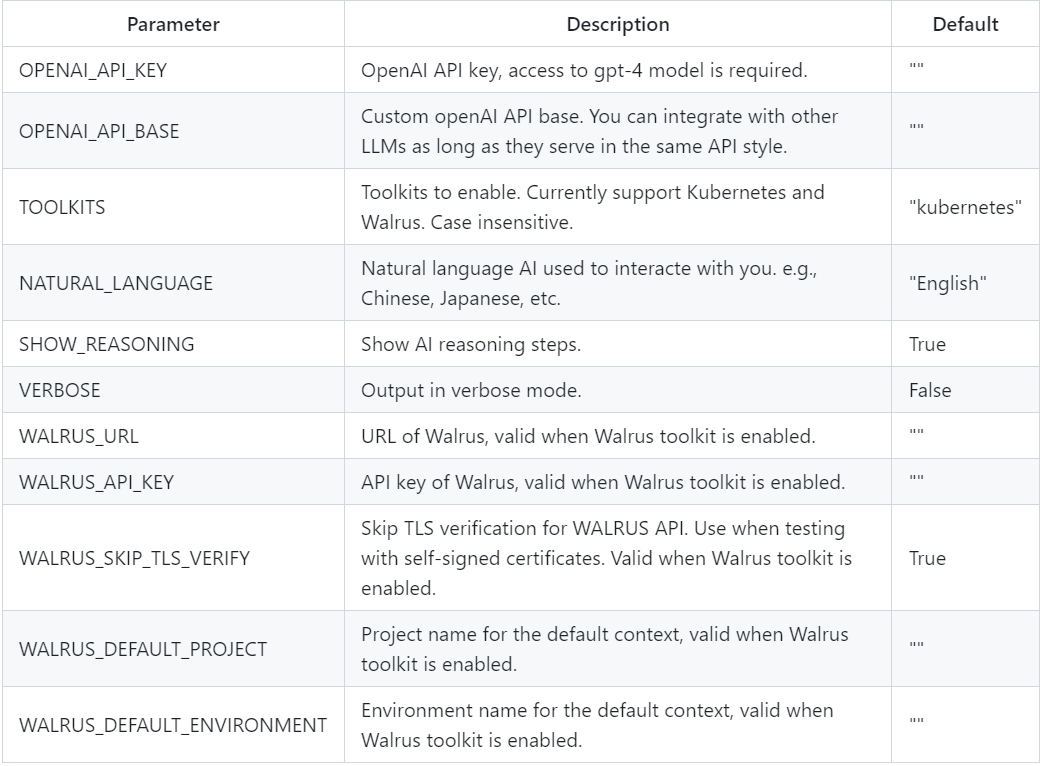
Below is more information about configuration, Appilot is configurable via environment variable or the envfile:
Then you can run Appilot to get started:
make run
Chat to Deploy Llama2 on AWS



Conclusion
In this blog, we've embarked on a journey to explore the deployment of Llama2, using Appilot and Walrus. We've witnessed how these powerful tools can simplify the complex process of deployment.
In conclusion, as demonstrated in this blog, both Appilot and Walrus stand as indispensable allies in the face of the intricate challenges of application deployment. What's even more enticing is that both these tools are open-source, inviting you to download and give them a try!
Appilot: https://github.com/seal-io/appilot



